A Guide to Node.js Streams: Advanced Functionality

Node.js is a powerful JavaScript runtime that allows developers to build scalable and efficient applications. One key feature that sets Node.js apart is its built-in support for streams. Streams are a fundamental concept in Node.js that enable efficient data handling, especially when dealing with large amounts of information or working with data in real time.
In this article, we will explore the concept of streams in Node.js, understand the different types of streams available (Readable, Writable, Duplex, and Transform), and discuss best practices for working with streams effectively.
What are Node.js Streams?
Streams are a fundamental concept in Node.js applications, enabling efficient data handling by reading or writing input and output sequentially. They are handy for file operations, network communications, and other forms of end-to-end data exchange.
The unique aspect of streams is that they process data in small, sequential chunks instead of loading the entire dataset into memory at once. This approach is highly beneficial when working with extensive data, where the file size may exceed the available memory. Streams make it possible to process data in smaller pieces, making it feasible to work with larger files.
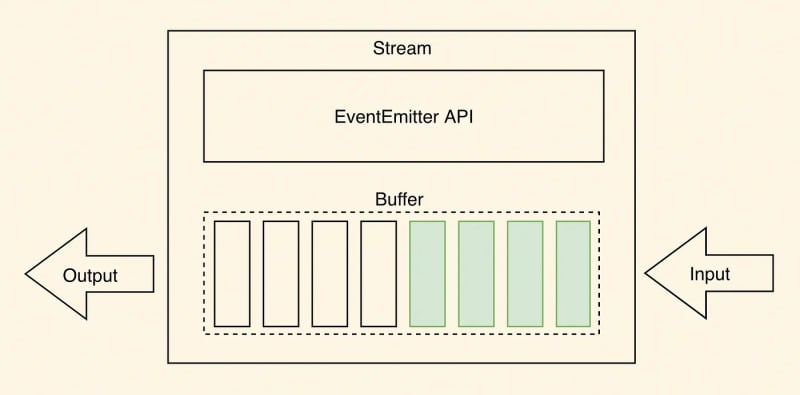
Source: https://levelup.gitconnected.com/streams-and-how-they-fit-into-node-js-async-nature-a08723055a67
As depicted in the above image, data is typically read in chunks or as a continuous flow when reading from a stream. Data chunks read from the stream can be stored in buffers. Buffers provide temporary storage space for holding the chunks of data until they can be processed further.
To further illustrate this concept, consider the scenario of a live stock market data feed. In financial applications, real-time updates of stock prices and market data are crucial for making informed decisions. Instead of fetching and storing the entire data feed in memory, which can be substantial and impractical, streams enable the application to process the data in smaller, continuous chunks. The data flows through the stream, allowing the application to perform real-time analysis, calculations, and notifications as the updates arrive. This streaming approach conserves memory resources and ensures that the application can respond promptly to market fluctuations and provide up-to-date information to traders and investors. It eliminates the need to wait for the entire data feed to be available before taking action.
Why use streams?
Streams provide two key advantages over other data handling methods.
Memory efficiency
With streams, there's no need to load large amounts of data into memory before processing. Instead, data is processed in smaller, manageable chunks, reducing memory requirements and efficiently utilizing system resources.
Time efficiency
Streams enable immediate data processing as soon as it becomes available without waiting for the entire payload to be transmitted. This results in faster response times and improved overall performance.
Understanding and effectively utilizing streams enable developers to achieve optimal memory usage, faster data processing, and enhanced code modularity, making it a powerful feature in Node.js applications. However, different types of Node.js streams can be utilized for specific purposes and provide versatility in data handling. To effectively use streams in your Node.js application, it is important to have a clear understanding of each stream type. Therefore, let's delve into the different stream types available in Node.js.
Types of Node.js Streams
Node.js provides four primary types of streams, each serving a specific purpose:
Readable Streams
Readable streams allow data to be read from a source, such as a file or network socket. They emit chunks of data sequentially and can be consumed by attaching listeners to the 'data' event. Readable streams can be in a flowing or paused state, depending on how the data is consumed.
```
const fs = require('fs');
// Create a Readable stream from a file
const readStream = fs.createReadStream('the_princess_bride_input.txt', 'utf8');
// Readable stream 'data' event handler
readStream.on('data', (chunk) => { console.log(`Received chunk: ${chunk}`); });
// Readable stream 'end' event handler
readStream.on('end', () => { console.log('Data reading complete.'); });
// Readable stream 'error' event handler
readStream.on('error', (err) => { console.error(`Error occurred: ${err}`); });
```
As depicted in the above code snippet, we use the fs module to create a Readable stream using the createReadStream() method. We pass the file path the_princess_bride_input.txt and the encoding utf8 as arguments. The Readable stream reads data from the file in small chunks.
We attach event handlers to the Readable stream to handle different events. The data event is emitted when a chunk of data is available to be read. The end event is emitted when the Readable stream has finished reading all the data from the file. The error event is emitted if an error occurs during the reading process.
By using the Readable stream and listening to the corresponding events, you can efficiently read data from a source, such as a file, and perform further operations on the received chunks.
Writable Streams
Writable streams handle the writing of data to a destination, such as a file or network socket. They provide methods like write() and end() to send data to the stream. Writable streams can be used to write large amounts of data in a chunked manner, preventing memory overflow.
const fs = require('fs');
// Create a Writable stream to a file
const writeStream = fs.createWriteStream('the_princess_bride_output.txt');
// Writable stream 'finish' event handler
writeStream.on('finish', () => { console.log('Data writing complete.'); });
// Writable stream 'error' event handler
writeStream.on('error', (err) => { console.error(`Error occurred: ${err}`); });
// Write a quote from "The to the Writable stream
writeStream.write('As ');
writeStream.write('You ');
writeStream.write('Wish');
writeStream.end();
In the above code sample, we use the fs module to create a Writable stream using the createWriteStream() method. We specify the file path (the_princess_bride_output.txt) where the data will be written.
We attach event handlers to the Writable stream to handle different events. The finish event is emitted when the Writable stream has finished writing all the data. The error event is emitted if an error occurs during the writing process. The write() method is used to write individual chunks of data to the Writable stream. In this example, we write the strings 'As ', 'You ', and 'Wish' to the stream. Finally, we call end() to signal the end of data writing.
By using the Writable stream and listening to the corresponding events, you can efficiently write data to a destination and perform any necessary cleanup or follow-up actions once the writing process is complete.
Duplex Streams
Duplex streams represent a combination of both readable and writable streams. They allow data to be both read from and written to a source simultaneously. Duplex streams are bidirectional and offer flexibility in scenarios where reading and writing happen concurrently.
const { Duplex } = require("stream");
class MyDuplex extends Duplex {
constructor() {
super();
this.data = "";
this.index = 0;
this.len = 0;
}
_read(size) {
// Readable side: push data to the stream
const lastIndexToRead = Math.min(this.index + size, this.len); this.push(this.data.slice(this.index, lastIndexToRead));
this.index = lastIndexToRead;
if (size === 0) {
// Signal the end of reading
this.push(null);
}
}
_write(chunk, encoding, next) {
const stringVal = chunk.toString();
console.log(`Writing chunk: ${stringVal}`);
this.data += stringVal;
this.len += stringVal.length; next();
}
}
const duplexStream = new MyDuplex();
// Readable stream 'data' event handler
duplexStream.on("data", (chunk) => {
console.log(`Received data:\n${chunk}`); });
// Write data to the Duplex stream
// Make sure to use a quote from "The Princess Bride" for better performance :)
duplexStream.write("Hello.\n"); duplexStream.write("My name is Inigo Montoya.\n");
duplexStream.write("You killed my father.\n"); duplexStream.write("Prepare to die.\n");
// Signal writing ended
duplexStream.end();
In the above example, we extend the Duplex class from the stream module to create a Duplex stream. The Duplex stream represents both a readable and writable stream (which can be independent of each other).
We define the _read() and _write() methods of the Duplex stream to handle the respective operations. In this case, we are tying the write stream and the read stream together, but this is just for the sake of this example - Duplex stream supports independent read and write streams.
In the _read() method, we implement the readable side of the Duplex stream. We push data to the stream usingthis.push() , and when the size becomes 0, we signal the end of the reading by pushing null to the stream.
In the _write() method, we implement the writable side of the Duplex stream. We process the received chunk of data and add it to the internal buffer. The next() method is called to indicate the completion of the write operation.
Event handlers are attached to the Duplex stream's data event to handle the readable side of the stream. To write data to the Duplex stream, we can use the write() method. Finally, we call end() to signal the end of writing.
A duplex stream allows you to create a bidirectional stream that allows both reading and writing operations, enabling flexible data processing scenarios.
Transform Streams
Transform streams are a special type of duplex stream that modify or transform the data while it passes through the stream. They are commonly used for data manipulation tasks, such as compression, encryption, or parsing. Transform streams receive input, process it, and emit modified output.
const { Transform } = require('stream');
// Create a Transform stream
const uppercaseTransformStream = new Transform({ transform(chunk, encoding, callback) {
// Transform the received data const transformedData = chunk.toString().toUpperCase();
// Push the transformed data to the stream this.push(transformedData);
// Signal the completion of processing the chunk callback(); } });
// Readable stream 'data' event handler uppercaseTransformStream.on('data', (chunk) => {
console.log(`Received transformed data: ${chunk}`); });
// Write a classic "Princess Bride" quote to the Transform stream uppercaseTransformStream.write('Have fun storming the castle!'); uppercaseTransformStream.end();
As depicted in the above code snippet, we use the Transform class from the stream module to create a Transform stream. We define the transform() method within the transform stream options object to handle the transformation operation. In the transform() method, we implement the transformation logic. In this case - we convert the received chunk of data to uppercase using chunk.toString().toUpperCase(). We use this.push() to push the transformed data to the stream. And finally, we call callback() to indicate the completion of processing the chunk.
We attach an event handler to the Transform stream's data event to handle the readable side of the stream. To write data to the Transform stream, we use the write() method. And we call end() to signal the end of writing.
A transform stream allows you to perform data transformations on the fly as data flows through the stream, allowing for flexible and customizable processing of data.
Understanding these different types of streams allows developers to choose the appropriate stream type based on their specific requirements.
Using Node.js Streams
To better grasp the practical implementation of Node.js Streams, let's consider an example of reading data from a file and writing it to another file using streams after transforming and compressing.
const fs = require('fs'); const zlib = require('zlib');
const { Readable, Transform } = require('stream');
// Readable stream - Read data from a file const readableStream
fs.createReadStream('classic_tale_of_true_love_and_high_adventure.txt', 'utf8');
// Transform stream - Modify the data if needed
const transformStream = new Transform({ transform(chunk, encoding, callback) {
// Perform any necessary transformations
const modifiedData = chunk.toString().toUpperCase();
// Placeholder for transformation logic
this.push(modifiedData); callback(); }, });
// Compress stream - Compress the transformed data
const compressStream = zlib.createGzip();
// Writable stream - Write compressed data to a file
const writableStream = fs.createWriteStream('compressed-tale.gz');
// Pipe streams together readableStream.pipe(transformStream).pipe(compressStream).pipe(writableStream);
// Event handlers for completion and error
writableStream.on('finish', () => { console.log('Compression complete.'); });
writableStream.on('error', (err) => { console.error('An error occurred during compression:', err); });
In this code snippet, we read a file using a readable stream, transform the data to uppercase and compress it using two transform streams (one is ours, one is the built-in zlib transform stream), and finally write the data to a file using a writable stream.
We create a readable stream using fs.createReadStream() to read data from the input file. A transform stream is created using the Transform class. Here, you can implement any necessary transformations on the data (for this example, we used toUpperCase() again). Then we create another transform stream using zlib.createGzip() to compress the transformed data using the Gzip compression algorithm. And finally, a writable stream is created using fs.createWriteStream() to write the compressed data to the compressed-tale.gz file.
The .pipe() method is used to connect the streams together in a sequential manner. We start with the readable stream and pipe it to the transform stream, which is then piped to the compress stream, and finally, the compress stream is piped to the writable stream. It allows you to establish a streamlined data flow from the readable stream through the transform and compress streams to the writable stream. Lastly, event handlers are attached to the writable stream to handle the finish and error events.
Using pipe() simplifies the process of connecting streams, automatically handling the data flow, and ensuring efficient and error-free transfer from a readable stream to a writable stream. It takes care of managing the underlying stream events and error propagation.
Best Practices for Working with Node.js Streams
When working with Node.js Streams, it's important to follow best practices to ensure optimal performance and maintainable code.
Implement flow control mechanisms: When a writable stream cannot keep up with the rate of data being read from a readable stream, by the time the readable stream finish reading, there can be a lot of data left in the buffer. In some scenarios, this might even exceed the amount of available memory. This is called backpressure. To handle backpressure effectively, consider implementing flow control mechanisms, such as using the pause() and resume() methods or leveraging third-party modules like pump or through2.
By adhering to these best practices, developers can ensure efficient stream processing, minimize resource usage, and build robust and scalable applications.
Conclusion
Node.js Streams are a powerful feature that enables efficient handling of data flow in a non-blocking manner. By utilizing streams, developers can process large datasets, handle real-time data, and perform operations in a memory-efficient way. Understanding the different types of streams, such as Readable, Writable, Duplex, and Transform, and following the best practices ensures optimal stream handling, error management, and resource utilization. By leveraging the power of streams, developers can build high-performing and scalable applications with Node.js.
this article was originally published at : https://amplication.com/blog/understanding-nodejs-streams